
Field Log: AI Engineering • 6 min read
When developers build applications with large language models (LLMs), they often blame the model when things go wrong. If the output is buggy or slow, they assume the model is at fault. However, AI performance is not a single layer. It is built on three distinct layers: the harness, the model, and the serving infrastructure.
Layer 1: The Harness (Orchestration Software)
The harness is the software running on your machine or server that calls the model API. It manages how the model interacts with the outside world. Examples of harnesses include developer tools like Claude Code, Codex, and OMP, as well as the chat websites you visit in your browser.
The harness is often the biggest bottleneck in AI agent performance. It controls the system prompts, tools, subagents, and file-editing scripts. A poorly designed harness can consume up to eight times more tokens for the exact same programming task because it feeds too much context or uses inefficient edit diff structures. If your agent gets stuck in loops, it is usually a bug in the harness, not the model.
Layer 2: The Model (Neural Network Weights)
The model is the actual neural network. It consists of trained weight values hosted remotely by providers. This is the brain that receives your prompt and generates tokens. When people benchmark performance using evaluations like SWE-bench, they are measuring the model layer under controlled conditions.
Layer 3: Serving and Inference (Compute Hardware)
Serving and inference refer to the cloud servers and chip hardware hosting the model. The speed and quality of a model vary depending on how it is hosted:
- Hardware Speed: Specialized chips like Tensor Processing Units (TPUs) or high-bandwidth GPUs dictate how fast the model returns answers.
- Dynamic Quantization: During peak hours, hosting providers may compress model weights (quantization) to save server memory. This makes the model faster but noticeably less intelligent.
- Infrastructure Consistency: Vertical integration (owning both the models and the physical cloud network) yields much more reliable performance compared to fragmented multi-cloud hosting setups.
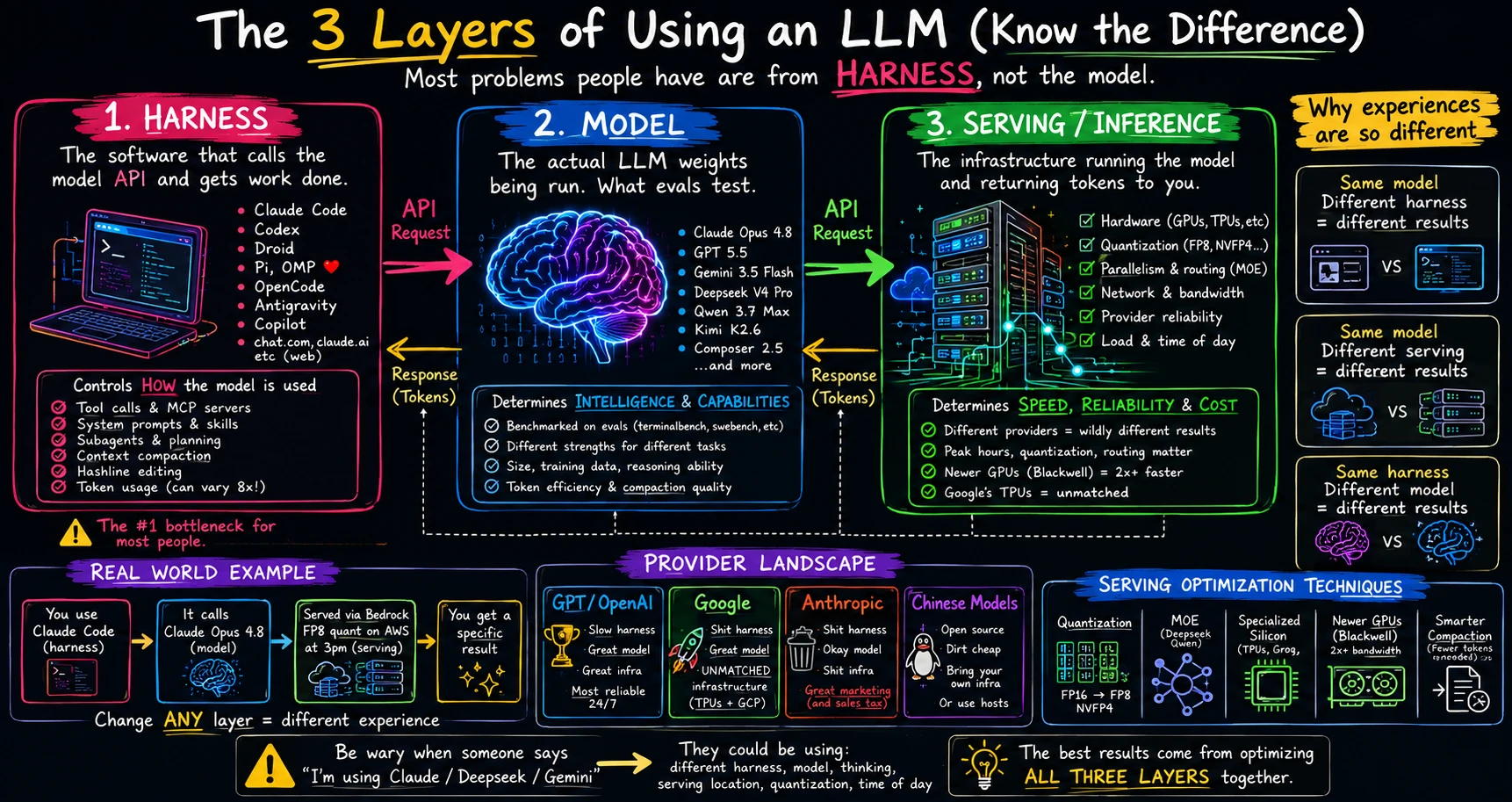
The Real-World Impact of the Triad
Confusing these layers leads to frustration. For example, a model might perform beautifully on Bedrock using an optimized harness at 2 AM. Yet, the same model might feel useless when run during peak business hours on a cheap subscription served at a lower memory precision.
When evaluating AI agents, be wary of simple statements like 'Model X is better than Model Y.' You must look at the entire stack:
Performance = Harness (Prompts & Tools) + Model (Brain Quality) + Serving (Latency & Precision)By selecting the right harness for your task and using stable hosting providers, you can unlock better results from the exact same model.
This analysis is inspired by the LLM system breakdown originally shared by Roy (@usr_bin_roygbiv on X). Understanding the distinction between harness, model, and serving is key to building reliable AI workflows.
Source Citation & Reference: This article is based on the LLM system architecture analysis shared by Roy in the thread: The Harness, the Model, and Serving Inference (X.com Post).